Kubernetes StatefulSet으로 MongoDB 구성하기
DevOps/Kubernetes
· 2025-02-14

들어가며
가장 해보고 싶던 정리다. 뭔가 기능 하나를 찾아보기위해 2-3가지 이상의 공식 문서와 정리글을 여기저기서 찾아보면서 오래 걸려 구현된 기능들을 현재 게시글 하나에 축약해서 넣어보려고 한다. 'mongoDB'를 쿠버네티스에 배포하고 싶다거나 데이터베이스를 배포하기하는 과정과 그 과정 속에서 생기는 물음들을 해소하고자 하는 분들에게 도움이 될 글이라 생각한다.
...
 Kubernetes
Kubernetes
Kubernetes
쿠버네티스라고 검색하면 컨테이너 오케스트레이션이라고 나온다. 이는 컨테이너 형태로 배포와 서비스 관리 및 유지보수에 필요한 다양한 기능들을 제공해주는 쿠버네티스에 대하여 완벽하게 묘사해주는 단어이다. 우리가 자고 있는 시간에도 서버 부하에 대응하여 오토스케일링이나 로깅, 모니터링을 지원하고, 재시작을 통한 장애 복구 기능도 제공해준다. 이번 게시글에서는 이 쿠버네티스를 통하여 데이터베이스를 배포하기 위해 필요한 리소스와 그 과정에 대해 정리해본다.
StatefulSet for MongoDB
MongoDB는 샤딩을 통하여 데이터베이스를 여러 서버에 분산 저장을 하여 대규모 트래픽과 데이터 처리하는 데 유리한 '상태 저장형 애플리케이션'이라고 많이 알려져있다. BSON이라는 이진 직렬화 형식을 통해 일반 텍스트 형식보다 적은 용량을 사용하고 처리 속도가 빠르다는게 장점이다.(현재 백엔드 프로젝트가 Go로 되어있는데, Data Access Layer에서 처리되는 로직에 bson 타입으로 채워져있는 것도 이러한 이유 때문이다.) 유연한 스키마와 Replica Set 기능을 통한 고가용성까지 보장하는 MongoDB는 왜 반드시 StatefulSet 형태로 배포되어야할까?
최소 단위, 파드(Pod)
데이터베이스를 '배포'한다고 했다. 이를 위해 우리는 '파드'라는 개념에 대해 알고 있어야한다. 파드는 쿠버네티스에서 가장 작은 배포 단위이며, 하나 이상의 컨테이너가 함께 묶여 동작하는 단위이다. 일련의 프로세스를 처리하기 위해 잠시 존재하는 작은 일회성 리소스라고 보면 된다.
"일회성이라고? 데이터베이스를 일회성 리소스에 배포하는게 말이 되나?"
당연히 말이 안된다. 이를 위해서는 파드가 통신하는 방식을 이해해야한다. 실제 파드를 생성하면 [resoure-name]-7bdc5d94c6-8lfmj 이러한 무작위한 문자열이 이름 뒤에 붙은 상태로 배포된다. 쿠버네티스는 중복 검증과 리소스 간 독립성을 유지하기 위해 네임이 규칙을 지원한다.(이 규칙도 변경할 수 있으나 구체적으로 다루진 않는다.) 그렇기 때문에 외부에서 이 파드와 통신하기 위해서 일관된 경로의 이름이 필요하다. 그 역할을 해주는 것이 **서비스(Service)**다.
서비스(Service)
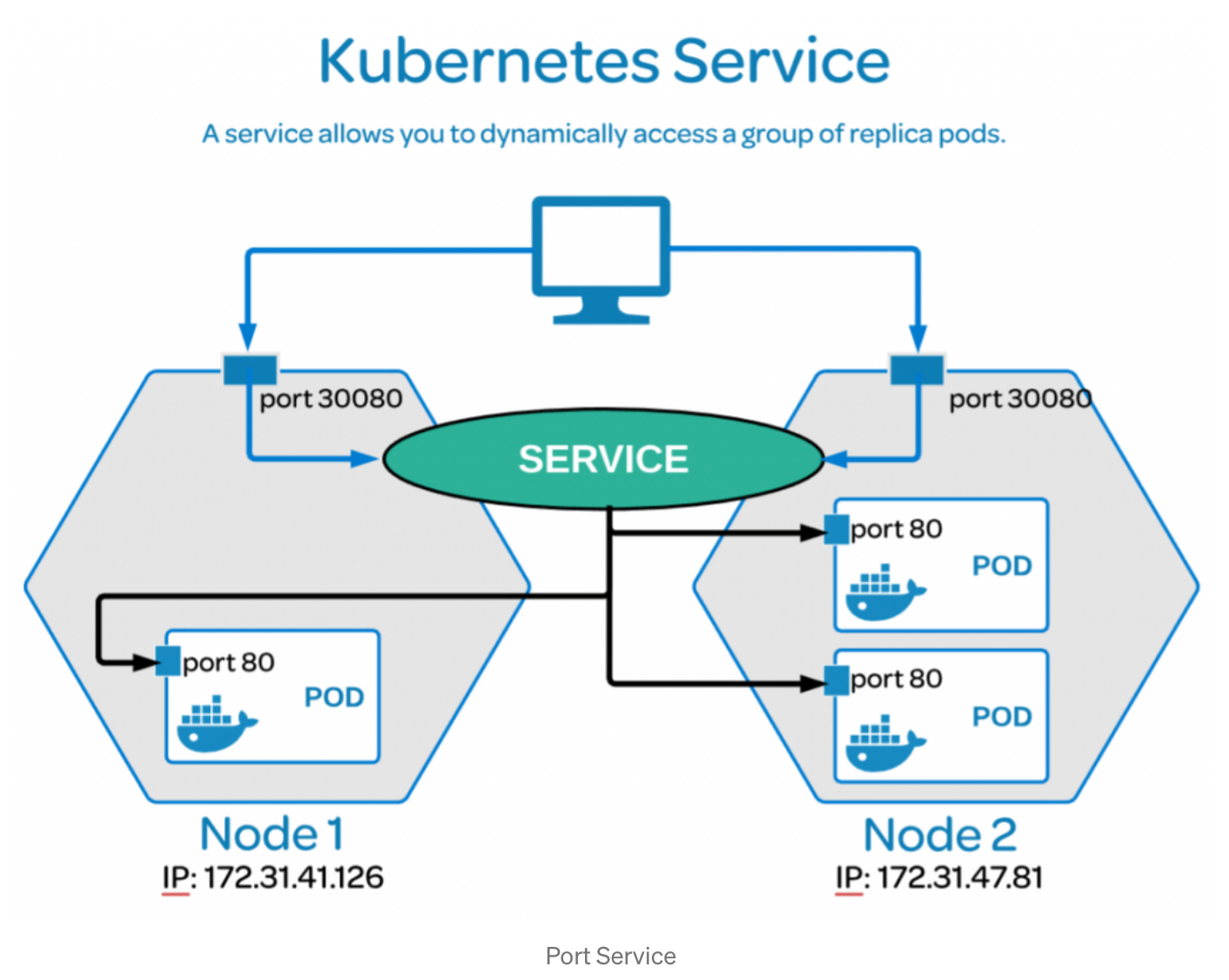
서비스는 파드를 외부에서 접근할 수 있도록 네트워크 레이어를 제공하는 일종의 리소스다. 일회성 특성을 가지는 파드는 새로 생성될 때마다 IP 주소가 변경된다. 그렇기에 특정 파드를 감지하기 위하여 서비스는 고정된 DNS 이름을 제공하여 지속적인 네트워크 통신이 가능하도록 한다. 따라서, 서비스는 파드들이 계속 교체되어도 일정한 주소로 접근할 수 있는 방법을 제공한다.
추가적으로, 파드와 서비스는
label과selector속성으로 연결된다. 당연히, 네임스페이스는 무조건 동일해야한다.
Deployment와 StatefulSet
이제 최소 단위 파드와 서비스를 알아보았으니, 애플리케이션이 배포되는 리소스 형태를 알아보자. 상황을 가정해보자. 애플리케이션이 하나의 인스턴스만 실행되고 있다면, 장애가 발생했을 때 애플리케이션의 가용성이 떨어지기 마련이다. 이를 위해 쿠버네티스는 여러 개의 인스턴스(파드)를 동시에 실행하고 관리하게 해주는 리소스를 제공해준다. 이게 바로 배포를 위한 일반적인 형태인 Deployment다.
Deployment의 필요성은 크게 네 가지로 설명된다.
-
고가용성: 여러 파드들을 배포하고, 하나가 장애나도 다른 파드가 계속 동작되어 정상적인 운영 관리를 보장한다.
-
자동화된 업데이트와 롤백: 새로운 버전의 애플리케이션을 배포할 때, 쿠버네티스는 롤링 업데이트를 통해 점진적으로 파드를 교체하여 애플리케이션 다운타임 없이 업데이트를 진행한다. 이 과정에서 문제가 발생하더라도 롤백 기능을 통해 쉽게 복구 가능하다.
-
스케일링: 일정 기준치를 설정하여 파드를 자동 추가 및 제거가 가능하다.(HPA에 대하나 게시글로 따로 정리하면 좋곘다.)
-
자체 복구 기능: 파드가 실패하거나 오류가 발생하면, Deployment는 새로운 파드를 자동으로 생성한다.
"그러면 데이터베이스도 Deployment kind로 배포하면 되는거 아니야? StatefulSet은 뭔데?"
Deployment는 주로 무상태 애플리케이션을 위한 것이지만, 데이터베이스와 같은 상태 저장형 애플리케이션의 경우 자신과 알맞는 고유한 특성이 고려되어야한다. 상태 저장형 애플리케이션은 각 인스턴스가 데이터를 저장하고 있어야하며, 파드의 순서와 고유한 식별자가 매우 중요하다.
"웬 순서와 고유한 식별자?"라는 생각이 들 수 있다. 순서와 고유한 식별자가 중요한 이유는 데이터베이스 인스턴스 간 데이터 일관성과 상태를 유지하기 위함이다. 파드가 고유한 네트워크 식별자를 가져야 파드가 종료 또는 재시작이 되어도 동일한 식별자를 통해 데이터베이스로 접근할 수 있다. 뒤에 더 자세히 설명하겠지만 MongoDB는 Replica Set을 구성할 때, Primary와 Secondary 노드 간 역할이 고장되기 때문에 각 노드의 역할을 유지하도록 보장이 되어야한다.
Deployment는 파드가 재시작될 때마다 이름과 네트워크 ID가 변경되어 클라이언트가 어떤 파드가 Primary인지 추측하기가 어려워진다. 이렇게 되면 데이터베이스 간 통신과 데이터 일관성이 깨진다.이러한 Deployment가 고려하지 못하는 특성들을 고려해주는 리소스가 바로 StatefulSet이다.
StatefulSet
StatefulSet은 상태 저장형(Stateful) 애플리케이션을 관리하기 위해 쓰인다. StatefulSet은 파드들이 고유한 네트워크 ID를 가지고, 순차적으로 파드를 배포 및 종료시켜 각각 고유한 스토리지를 유지할 수 있게 한다. 예를 들어, 데이터베이스 클러스터에서 Primary가 먼저 준비되지 않으면 Secondary 파드는 제대로 동작하지 않을 수 있다. StatefulSet은 이러한 순서와 고유성을 보장해준다.
StatfulSet으로 배포된 파드들은 앞서 Deployment가 배포하는 파드의 네이밍과는 다르다.
- Deployment Pod :
nginx-7bdc5d94c6-8lfmj,nginx-7bdc5d94c6-m4b8v - StatefulSet Pod :
database-0,database-1,database-2
StatefulSet 전용 서비스: Headless Service !
이제 StatefulSet까지는 왜 써야하는지 명확해졌다. 여기서 다음 새로운 리소스들을 살펴보기 앞서, 서비스에 대한 추가적인 제안사항이 있다. 일반적인 서비스는 쿠버네티스에서 파드들의 IP 주소를 하나의 DNS 이름으로 매핑하여, 요청이 들어오면 해당 이름을 가진 파드 중 하나로 트래픽을 **rr방식(Round Robin)**으로 분배한다. 하지만 StatefulSet은 각 파드가 고유한 ID와 순서를 가지고 있어야하므로, 로드 밸런싱 없이 각 파드에 고유한 DNS 엔트리를 할당하는 Headless Service가 필요하다. 즉, Headless Service는 파드별 고유성과 순서를 보장하기 위해 각 파드에 대해 개별 DNS 레코드를 생성하며, 이를 통해 클라이언트는 각 파드의 고유 IP에 접근할 수 있게 된다.
라운드로빈 방식이란? : 여러 서버 또는 파드에 요청을 순차적으로 분배하여, 부하를 고르게 분산하기 위해 각 서버에 차례대로 요청을 전달하는 일종의 알고리즘이다. 이 작업은 kube-proxy가 수행하고, 트래픽을 서비스에 연결된 파드들로 분배될 때 iptables 또는 IPVS를 사용한다. 정리할게 참 많은데 이건 또 다른 게시글로..
Headless Service 설정은 clusterIP 속성값에 None을 지정해주면 끝난다. 그러면 쿠버네티스는 클러스터 IP를 생성하지 않고 로드 밸런싱 없이 각 파드에 대해 DNS 엔트리를 생성한다. 당연히 StatefulSet과 연결하기 위하여 labels, selector 설정은 필수이며, StatefulSet은 serviceName 속성에 Headless Service명을 넣어준다.
1# StatefulSet yaml 2apiVersion: apps/v1 3kind: StatefulSet 4metadata: 5 name: statefulset-sample 6spec: 7 serviceName: mongo-headless # Headless Service와 연결 8 replicas: 3 9 selector: 10 matchLabels: 11 app: 0biglife 12 template: 13 metadata: 14 labels: 15 app: 0biglife 16 spec: 17 containers: 18 ... 19 20# Headless Service 21apiVersion: v1 22kind: Service 23metadata: 24 name: mongo-headless 25 labels: 26 app: 0biglife 27spec: 28 clusterIP: None # Headless Service 29 selector: 30 app: 0biglife 31 ports: 32 - port: 80 33 targetPort: 80
StorageClass, PersistentVolume(PV), PersistentVolumeClaim(PVC)
데이터베이스가 배포되는 형태인 StatefulSet에 데이터를 저장 관리하기 위해, 고유한 스토리지를 제공할 필요가 있다. 이를 위한 핵심 리소스가 StorageClass, PV, PVC다. 비교적 간단한 내용이라 짧게 정리해본다.
StorageClass
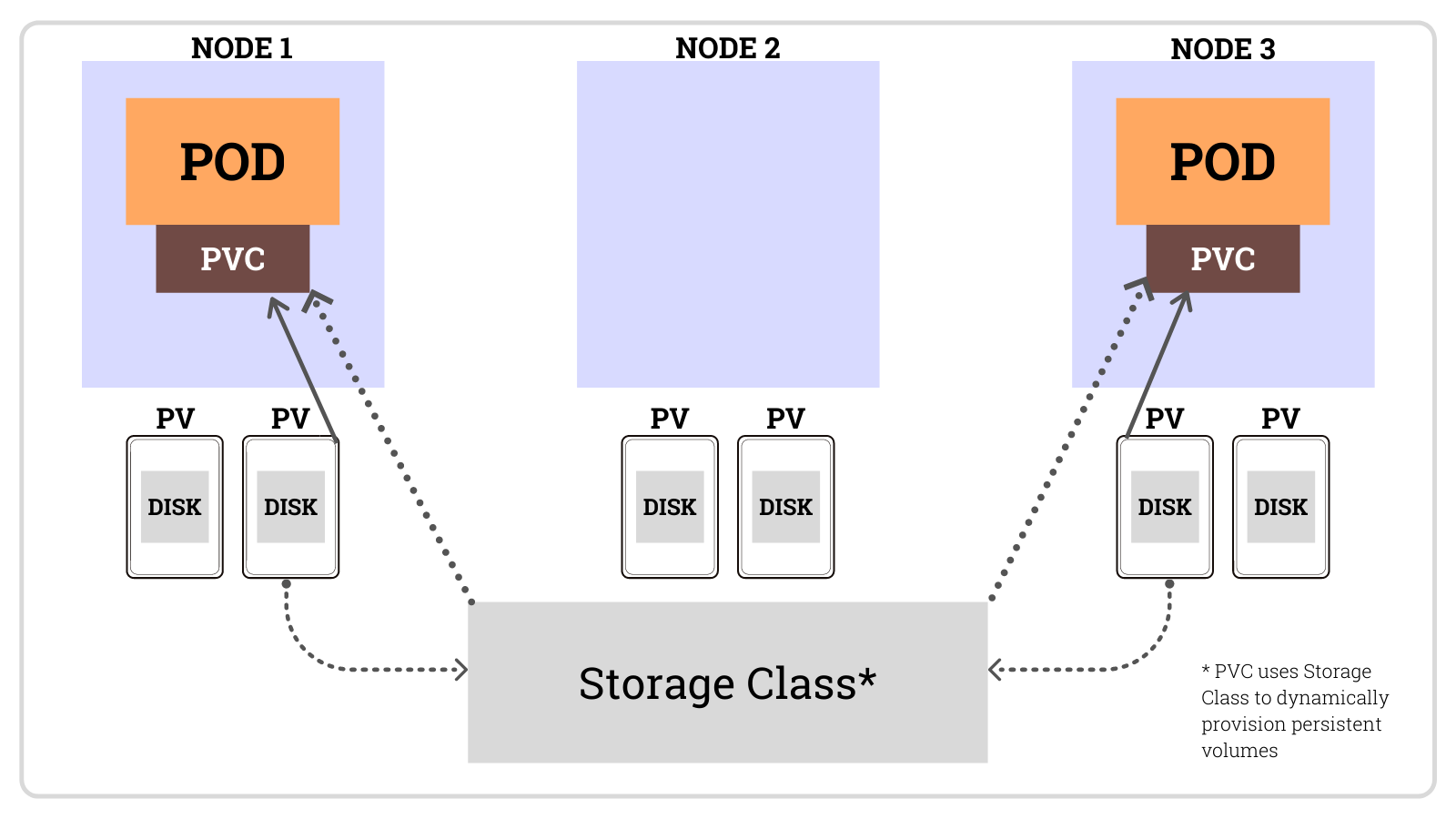
StorageClass는 쿠버네티스에서 스토리지를 동적으로 할당하는 방법을 정의하는 리소스다. 각 클라우드 프로바이더는 다양한 스토리지 옵션을 제공하고, 이를 관리하기 위한 정책을 정의하는 역할을 한다.
1# StorageClass yaml 2allowVolumeExpansion: true 3apiVersion: storage.k8s.io/v1 4kind: StorageClass 5metadata: 6 name: azurefile 7provisioner: file.csi.azure.com 8reclaimPolicy: Delete 9volumeBindingMode: Immediate
-
allowVolumeExpansion : 볼륨 확장을 허용한다. 이미 생성된 볼륨의 크기를 동적으로 확장한다.
-
provisioner : 스토리지 프로비저닝을 담당하는 CSI 드라이버다. 현재 Azure 파일 기반 스토리지를 제공하는 프로비저너로, 이 속성을 통해 Azure 파일 시스템을 프로비저닝한다.
-
reclaimPolicy : 해당 스토리지 볼륨이 더 이상 사용되지 않으면 어떻게 처리될지를 정의한다. 현재
Delete로 설정되어있어 PVC가 삭제되면 볼륨도 같이 삭제된다. -
volumeBindingMode : 볼륨 바인딩 모드를 나타내며,
Immediate은 PVC가 생성되자마자 즉시 PV를 프로비저닝하고 바인딩하는 방식이다.
PersistentVolume(PV)
PV는 실제 물리적 또는 클라우드 스토리지를 나타내는 리소스이며, 클러스터 내에서 사용할 수 있는 저장 공간을 제공한다. 일종의 영구 저장소 제공 역할을 하는 PV는 StatefulSet 파드가 종료되거나 재시작되어도 데이터를 잃지 않아야하기 때문에, 각 파드에 맞는 영구 리토리지를 할다알 수 있는 PV가 필요하다. 즉, 파드가 죽거나 재시작되더라도 동일한 스토리지를 유지되기 위해 무조건 필요하다.
1# PV yaml 2apiVersion: v1 3kind: PersistentVolume 4metadata: 5 name: pv-sample 6spec: 7 capacity: 8 storage: 5Gi 9 accessModes: 10 - ReadWriteOnce 11 persistentVolumeReclaimPolicy: Retain 12 storageClassName: fast 13 hostPath: 14 path: /mnt/data
-
capacity : 스토리지 크기
-
accessModes : 스토리지 접근 모드(
ReadWriteOnce,ReadOnlyMany,ReadWriteMany등) -
persistentVolumeReclaimPolicy : PV를 사용한 후의 처리 방식을 정의한다.
Retain은 스토리지를 계속 유지시킨다.
PersistentVolumeClaim(PVC)
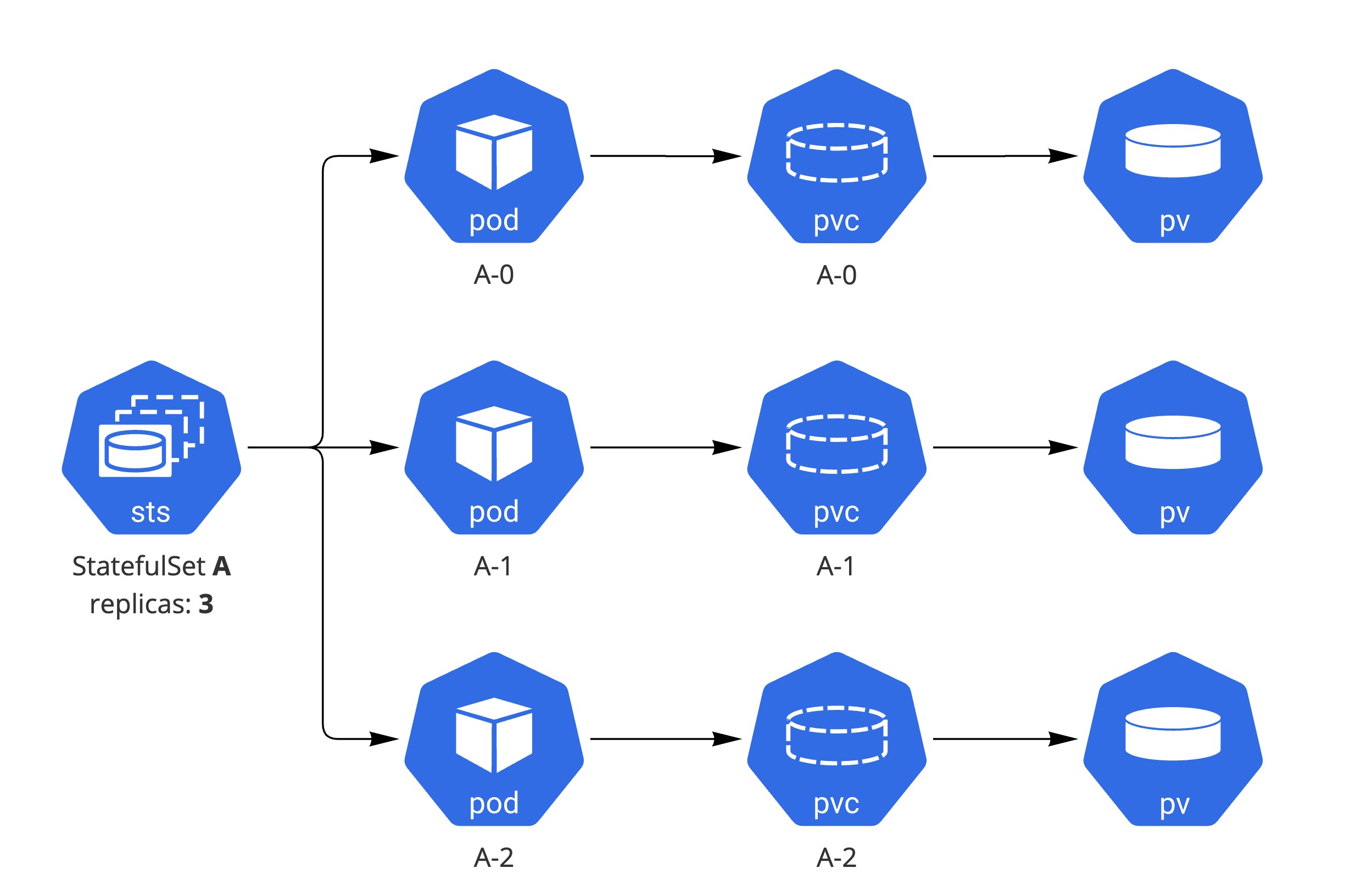
PVC는 파드가 필요한 스토리지를 요청하는 리소스다. PVC는 PV와 연결되며, 파드가 PVC를 통해 특정 크기와 속성의 스토리지를 요청하면 쿠버네티스는 이에 알맞는 PV를 할당시켜준다. 즉, 파드는 PVC를 사용하여 PV를 요청하고, 이를 통해 필요한 크기의 스토리지를 사용한다.
1# PVC yaml 2apiVersion: v1 3kind: PersistentVolumeClaim 4metadata: 5 name: pvc-sample 6spec: 7 accessModes: 8 - ReadWriteOnce 9 resources: 10 requests: 11 storage: 5Gi 12 storageClassName: fast
-
resources.requests.storage : PVC가 요청하는 스토리지의 크기
-
accessModes : 해당 스토리지가 어떤 방식으로 접근될 수 있는지를 정의
정리
여태까지 살펴본 StatefulSet은 파드의 고유한 네트워크 ID와 순차적 배포를 보장하며 Headless Service는 각 파드에 고유한 DNS 엔트리를 제공하여 MongoDB의 Replica Set 구성에서 필요한 안정적인 통신 경롤르 확보하고, StorageClass, PV, PVC는 각 파드가 재시작되거나 삭제되더라도 데이터를 영구적으로 보존하는 스토리지를 제공하는 역할을 수행한다. 위 구성을 통해 쿠버네티스 환경에서 mongoDB를 안정적이고 일관되게 배포할 수 있는 기반이 마련되었고, 이 구조를 바탕으로 mongoDB Replica Set을 배포하는 방법을 알아보자!
MongoDB Replica Set 구성
MongoDB Replica Set은 복제본을 의미하여 여러 개의 인스턴스로 관리됨을 전제로 한다. 레플리카 셋 구성은 안정적인 성능과 고가용성을 위하여 기본적으로 3개를 기준으로 하며, 구성은 하나의 Primary와 여러 개의 Secondary 노드로 구성된다. Primary 노드는 읽기와 쓰기 작업을 처리하고, Secondary 노드는 Primary로부터 데이터를 복제하여 읽기 전용으로 처리한다. 이러한 구성으로 MongoDB는 고가용성과 데이터 일관성을 보장한다.
-
Primary Node : 클러스터 내에서 유일하게 쓰기 작업을 처리하는 노드이며, 모든 쓰기 작업은 Primary에서 처리된 후 Secondary로 복제된다. 이를 통해 모든 Secondary는 Primary와 동일한 데이터를 유지하게 되며 데이터 손실을 방지한다.
-
Secondary Node : Primary 노드로부터 복제된 데이터를 저장하고 읽기 작업을 처리한다. Primary 노드가 장애를 일으킬 경우 하나의 Secondary 노드가 자동으로 Primary로 승격된다. 이를 통해 데이터베이스가 중단되지 않고 지속적으로 운영될 수 있다.
-
Arbiter Node : 데이터를 동기화하지 않으며, Primary 선정을 위한 투표권만 주어진다.
이 세 가지 노드를 조합하여 MongoDB를 PSS구조 또는 PSA 구조로 서버를 구성할 수 있다.(이번 예제에서는 PSS 구조로 구성한다.)
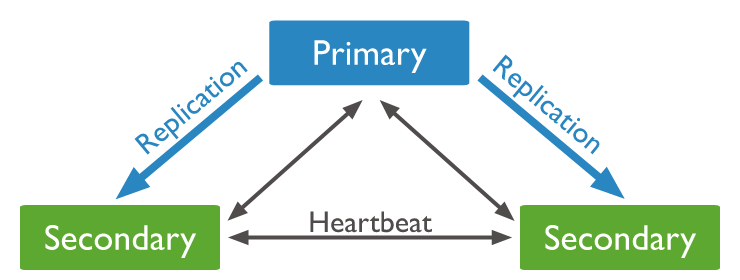 PSS Structure
PSS Structure
- PSS구조(Primary + Secondary + Secondary) : 하나의 Primary와 두 개의 Secondary 노드로 이루어진 구성이다. Primary 노드에 문제가 생길 경우, Secondary 노드 2개나 승격할 수 있기에 가장 높은 안정성을 보장한다.
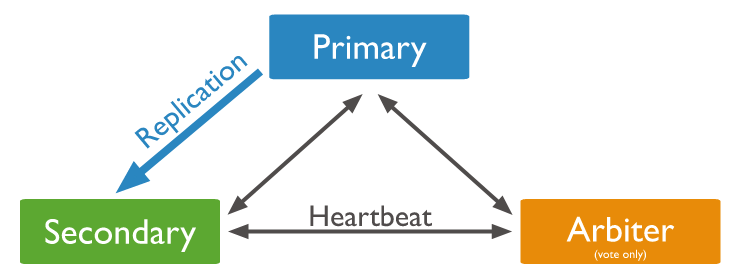 PSA Structure
PSA Structure
- PSA구조(Primary + Secondary + Arbiter) : 세 가지 노드가 하나씩 구성된 형태로, Arbiter 노드는 많은 리소스가 필요하지 않지만 실제 데이터를 담고 있지 않기에 PSS구조보다 비교적 고가용성이 떨어진다. Primary 노드가 장애를 일으킬 경우, Secondary 노드는 하나만 남기 때문에 데이터 복원력이 제한적일 수 있다. 주로 저장 리소스가 부족한 작은 애플리케이션이나, 비용 절감ㅇ르 우선시하는 서비스에 사용된다.
자, 이제 준비된 환경에서 MongoDB Replica Set을 직접 구성해보자. Replcia Set 구성을 위한 위 노드들에 대한 설정은 기본적으로 yaml을 통해 배포되는 StatefulSet의 내부 속성값으로 역할 분담을 설정할 수 없고, MongoDB 내부에서 설정과 관리가 이루어진다. 이번 예제에서는 3개의 파드를 가지는 mongo-sample 이름의 StatefulSet을 배포했다.
1apiVersion: apps/v1 2kind: StatefulSet 3metadata: 4 name: mongo-sample 5spec: 6 serviceName: <headless-service-name> 7 replicas: 3 8 ...
MongoDB Replica Set 설정
먼저 MongoDB 클러스터의 동작 방식을 시작하는 단계로서, Replica Set 초기화를 한다. 초기화하기 앞서 우리는 파드 내부에 접속해서 mongo cli를 입력해야하며, 이는 kubectl cli를 통해 가능하다.
- MongoDB Pod 접속
1# kubectl exec -it <mongodb-pod-name> -n <mongodb-pod-namespace> -- mongo 2# 현재 환경에서는 아래 CLI 입력 3kubectl exec -it mongo-sample-0 -n default -- mongo
- Replica Set 초기화
rs.initiate() 명령어를 통해 MongoDB가 Replica Set 모드에서 동작하도록 설정한다. 이를 통해 하나의 노드가 Primary로 지정된다.
1mongo --eval 'rs.initiate()'
- Secondary Node 추가
rs.add(~) 명령어를 통해 각 Pod의 역할을 자동으로 결정하고 관리한다.
1mongo --eval 'rs.add("mongo-sample-1.mongo-headless.default.svc.cluster.local:27017")' 2mongo --eval 'rs.add("mongo-sample-2.mongo-headless.default.svc.cluster.local:27017")'
성공적으로 Replica Set이 설정되었다면 아래와 같이 커맨드 입력창 앞에 Primary 가 보이면 된다.
마치며
데이터베이스가 쿠버네티스 클러스터 내부에 배포될 때 갖추어져야할 기본적인 것들에 대해 살펴보았고, MongoDB를 예제로 하여 세 개의 레플리카로 구성하는 방식을 구현하였다. 이 과정은 NIPA 인증서 취득을 하기 위해 개발하면서 정리한 내용들이다. 사실상 프론트엔드 개발자로서 커리어를 이어나가기에는 밀접한 관계는 없어보이지만, 개발을 좋아하고 내가 참여하는 프로젝트 애플리케이션이 관리되는 생애주기 관점에서 알아두면 충분히 가치있는 즐거운 지식(?)이라고 생각한다.
다만, 분명 한계점은 존재한다. 현재 있는 작은 회사에서의 운영 방식은 면접을 보는 회사에서 채택한 방식과는 조금 거리가 동떨어져있는 비효율적인 방식일 수도 있고, 시니어 개발자 아래서 일하면서 배울 수 있는 지식보다는 활용도나 기술력이 많이 부족할 수 있다. 문서를 찾아보고 서치를 해서 배우는 지식보다 좀 더 깊이 있는 노하우들을 습득하기 위해서 더 넓은 풀에 들어가는 것은 필연적인 일처럼 느껴진다. 잠시 게시글 주제와는 조금 관계없는 이야기까지 와버렸지만, 애플리케이션과 연관된 것들을 하나씩 경험하며 정리하다보면 결국 4,5년차에는 더욱 단단한 개발자가 되어있을거라는 말로 글을 마무리한다.